数据库索引有哪几种,怎样建立索引
的有关信息介绍如下:数据库索引的种类:
1、按照索引列值的唯一性,索引可分为唯一索引和非唯一索引
非唯一索引:B树索引
create index 索引名 on 表名(列名) tablespace 表空间名;
唯一索引:建立主键或者唯一约束时会自动在对应的列上建立唯一索引
2、索引列的个数:单列索引和复合索引
3、按照索引列的物理组织方式
B树索引
create index 索引名 on 表名(列名) tablespace 表空间名;
位图索引
create bitmap index 索引名 on 表名(列名) tablespace 表空间名;
反向键索引
create index 索引名 on 表名(列名) reverse tablespace 表空间名;
函数索引
create index 索引名 on 表名(函数名(列名)) tablespace 表空间名;
删除索引
drop index 索引名
重建索引
alter index 索引名 rebuild
索引的创建格式:
CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>
ON <schema>.<table_name>
(<column_name> | <expression> ASC | DESC,
<column_name> | <expression> ASC | DESC,...)
TABLESPACE <tablespace_name>
STORAGE <storage_settings>
LOGGING | NOLOGGING
COMPUTE STATISTICS
NOCOMPRESS | COMPRESS<nn>
NOSORT | REVERSE
PARTITION | GLOBAL PARTITION<partition_setting>
UNIQUE | BITMAP:指定UNIQUE为唯一值索引,BITMAP为位图索引,省略为B-Tree索引。
<column_name> | <expression> ASC | DESC:可以对多列进行联合索引,当为expression时即“基于函数的索引”
TABLESPACE:指定存放索引的表空间(索引和原表不在一个表空间时效率更高)
STORAGE:可进一步设置表空间的存储参数
LOGGING | NOLOGGING:是否对索引产生重做日志(对大表尽量使用NOLOGGING来减少占用空间并提高效率)
COMPUTE STATISTICS:创建新索引时收集统计信息
NOCOMPRESS | COMPRESS<nn>:是否使用“键压缩”(使用键压缩可以删除一个键列中出现的重复值)
NOSORT | REVERSE:NOSORT表示与表中相同的顺序创建索引,REVERSE表示相反顺序存储索引值
PARTITION | NOPARTITION:可以在分区表和未分区表上对创建的索引进行分区
使用USER_IND_COLUMNS查询某个TABLE中的相应字段索引建立情况
使用DBA_INDEXES/USER_INDEXES查询所有索引的具体设置情况。
在Oracle中的索引可以分为:B树索引、位图索引、反向键索引、基于函数的索引、簇索引、全局索引、局部索引等,下面逐一讲解:
一、B树索引:
最常用的索引,各叶子节点中包括的数据有索引列的值和数据表中对应行的ROWID,简单的说,在B树索引中,是通过在索引中保存排过续的索引列值与相对应记录的ROWID来实现快速查询的目的。其逻辑结构如图:

可以保证无论用户要搜索哪个分支的叶子结点,都需要经过相同的索引层次,即都需要相同的I/O次数。
B树索引的创建示例:
create index ind_t on t1(id) ;
注1:索引的针对字段创建的,相同字段不能创建一个以上的索引;
注2:默认的索引是不唯一的,但是也可以加上unique,表示该索引的字段上没有重复值(定义unique约束时会自动创建);
注3:创建主键时,默认在主键上创建了B树索引,因此不能再在主键上创建索引。
二、位图索引:
有些字段中使用B树索引的效率仍然不高,例如性别的字段中,只有“男、女”两个值,则即便使用了B树索引,在进行检索时也将返回接近一半的记录。
所以当字段的基数很低时,需要使用位图索引。(“低”的标准是取值数量 < 行数*1%)
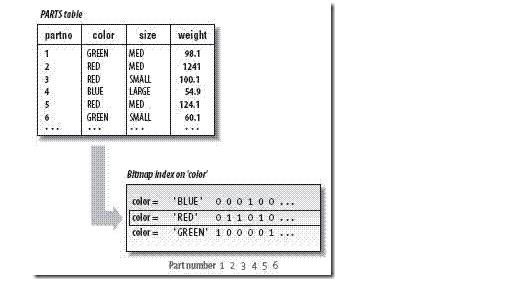
位图索引的逻辑结构如上图所示:索引中不再记录rowid和键值,而是将每个值作为一列,用0和1表示该行是否等于该键值(0表示否;1表示是)。其中位图索引的行顺序与原表的行顺序一致,可以在查询数据的过程中对应计算出行的原始物理位置。
位图索引的创建示例:
create bitmap index ind_t on t1(type);
注:位图索引不可能是唯一索引,也不能进行键值压缩。
三、反向键索引:
考虑这个情况:某一字段的值是1-1000顺序排列,建立B树索引后依旧递增,到后来该B数索引不断在后面增加分支,会形成如下如的不对称树:
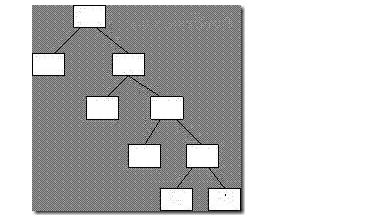
反向键索引是一种特殊的B树索引,在存储构造中与B树索引完全相同,但是针对数值时,反向键索引会先反向每个键值的字节,然后对反向后的新数据进行索引。例如输入2008则转换为8002,这样当数值一次增加时,其反向键在大小中的分布仍然是比较平均的。
反向键索引的创建示例:
create index ind_t on t1(id) reverse;
注:键的反转由系统自行完成。对于用户是透明的。
四、基于函数的索引:
有的时候,需要进行如下查询:select * from t1 where to_char(date,'yyyy')>'2007';
但是即便在date字段上建立了索引,还是不得不进行全表扫描。在这种情况下,可以使用基于函数的索引。其创建语法如下:
create index ind_t on t1(to_char(date,'yyyy'));
注:简单来说,基于函数的索引,就是将查询要用到的表达式作为索引项。
五、全局索引和局部索引:
这个索引貌似很复杂,其实很简单。总得来说一句话,就是无论怎么分区,都是为了方便管理。
具体索引和表的关系有三种:
1、局部分区索引:分区索引和分区表1对1
2、全局分区索引:分区索引和分区表N对N
3、全局非分区索引:非分区索引和分区表1对N
创建示例:
首先创建一个分区表
create table student
(
stuno number(5),
sname vrvhar2(10),
deptno number(5)
)
partition by hash (deptno)
(
partition part_01 tablespace A1,
partition part_02 tablespace A2
);
创建局部分区索引(1v1):
create index ind_t on student(stuno)
local(
partition part_01 tablespace A2,
partition part_02 tablespace A1
); --local后面可以不加
创建全局分区索引(NvN):
create index ind_t on student(stuno)
global partition by range(stuno)
(
partition p1 values less than(1000) tablespace A1,
partition p2 values less than(maxvalue) tablespace A2
); --只可以进行range分区
创建全局非分区索引(1vN)
create index ind_t on student(stuno) GLOBAL;